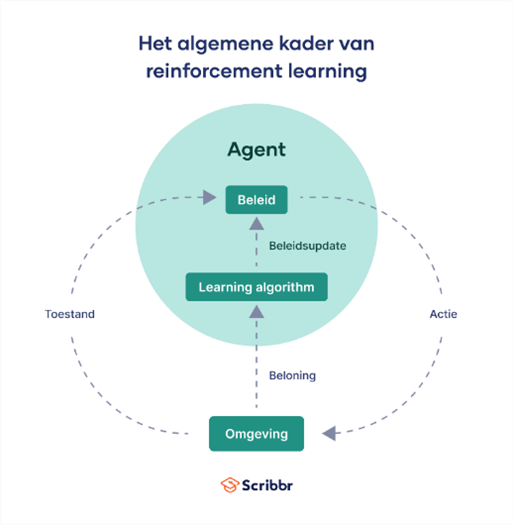
Reinforcement Learning
Reinforcement learning is een manier voor AI om een probleem op te lossen. Er wordt door middel van invoering aangegeven dat er een probleem is dat opgelost moet worden. De AI probeert op verschillende manieren het probleem op te lossen door gebruik te maken van zijn omgeving. Reinforcement learning is 1 van de 3 basisbenaderingen voor machine learning samen met super- en unsupervised learning. Deze methode wordt veel gebruikt voor zowel spellen als robotica. De methode is gericht op het geven van beloningen en straffen aan de AI waardoor die zichzelf kan verbeteren. Reinforcement learning kan voor vele verschillende dingen gebruikt worden zoals robotica en gamen. Deze leermethode wordt het meest gebruikt bij games. Reinforcement learning heeft wel een nadeel, het kan alleen toegepast worden als er een duidelijke beloning is op het einde van zijn rit. Daarnaast kan bij bijvoorbeeld een game het einddoel niet aangepast worden tijdens de run, aangezien de AI probeert het eerder vastgestelde einddoel te behalen kan hij moeilijk ineens switchen, zo kan het systeem ook moeilijk omgaan met verschillende levels. Het draait bij reinforcement learning namelijk om de omgeving waar het in bevind, als hij bij het eerste Mario level op het begin een schildpad tegenkomt gaat hij in het 2de level niet gelijk een schildpad kunnen vinden die op een andere plaats bevind. Hij zou in dit geval wel eerder detecteren dat de schildpad een gevaar is, maar hij zou niet weten wanneer dit gevaar is. Daarentegen zou hij waarschijnlijk wel het level eerder halen als hij al informatie heeft opgeslagen van eerdere levels/pogingen aangezien hij dan wel al weet wat hij in een scenario zou moeten doen.
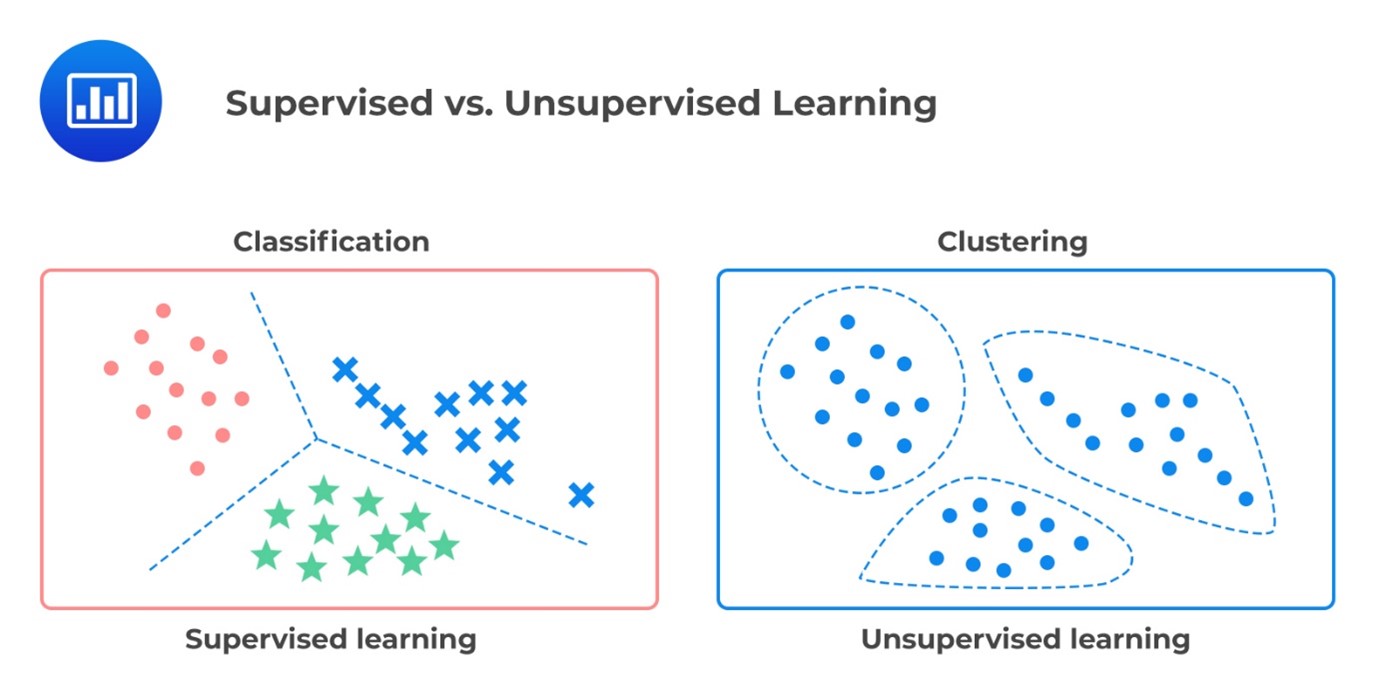
Supervised Learning
Supervised learning is een van de 3 takken van machine learning. Het houdt in dat je de AI een dataset geeft van te voren samen met een einddoel zoals sorteer de volgende data set met als klassen katten en honden. Vervolgens krijgt de supervised AI een dataset die groot genoeg is waarmee hij kan werken. Vervolgens gaat hij de klassen sorteren en laat hij zien product zien. De ontwikkelaar geeft vervolgens aan of het product goed genoeg is of dat hij nog niet voldoende is (te veel fouten). Indien niet goed, past de supervised AI zich aan tot dat bij eindproduct het aantal fouten geminimaliseerd is.
Unsupervised Learning
De laatste tak van Machine learning is unsupervised learning. Deze type AI heeft geen menselijke interventie nodig wanneer het bezig is. Vergeleken met supervised learning is unsupervised minder accuraat en ook minder vertrouwbaar. Een methode binnen unsupervised learning is clustering. Bij clustering zet de AI data die geen label heeft samen in een groep gestopt. Ze worden bij elkaar gezet door te kijken naar de overeenkomsten en verschillen. Clustering heeft verschillende types zoals exclusieve, hiërarchische en probabilistische clustering.
clusieve clustering: Exclusieve clustering zorgt ervoor dat je dataset uit maar één cluster kan bestaan. Een vorm van exclusieve clustering is K-means clustering. Bij K-means clustering kan je aangeven hoeveel zwaartepunten je wilt geven aan een dataset. Datapunten worden dan gegroepeerd bij het dichtstbijzijnde zwaartepunt. K-means clustering is handig om te gebruiken wanneer je iets wilt segmenteren. Hoe meer clusters betekent niet altijd hoe beter. Je moet het juiste aantal clusters vinden door middel van de trial and error methode.
Hiërarchische clustering: Bij hiërarchische clustering probeert je groepen die gelijkenissen met elkaar hebben samen te voegen tot het uiteindelijk 1 cluster wordt met alle data. Agglomeratief en verdeeldheid zijn de twee categorieën binnen hiërarchische clustering. Agglomeratieve clustering begin je met allemaal losse clusters die je probeert tot één grote cluster te krijgen. Met de verdeelheidsaanpak is het juist andersom, je gaat van één grote clusters tot losse clusters die gelijkenissen met elkaar hebben.
probabilistische clustering: De laatste vorm van clustering is probabilistische clustering. Hierbij cluster je op de basis van de waarschijnlijkheid dat iets in een cluster hoort. De datapunten met dezelfde hoogte worden dan bij elkaar gecategoriseerd. Een vorm binnen probabilistische clustering is het Gaussiaanse model. Bij het Gaussiaanse model ook wel bekend als Gaussian Mixture Model (GMM) is het gemiddelde van de datapunten niet bekend is. Als het wel bekend is wordt de ‘normale methode’ toegepast op de dataset om die te clusteren.